
CleanArchitectureについて
クリーンアーキテクチャについての自分の考えを備忘録としてまとめています。
クリーンアーキテクチャとは何か
- 「関心事の分離」を目的としてソースコードのレイヤーを分割する考え方のこと。これにより以下のようなメリットが得られる。
- テスト可能
- UI非依存
- データベース非依存
- フレームワーク非依存
- 基本的な構成ではソフトウェア領域を
Entity,UseCase,Adapter,Infrastructureの4つの層に分類する。層は同心円の形をしており、円の内側へのみ依存できる。Entityは企業のビジネスルールを扱うUseCaseはアプリケーションのルールを扱うAdapterは上位2レイヤーのフォーマットをInfrastructureのフォーマットへと変換するInfrastructureはデータベースやフレームワークなどのツールを扱う

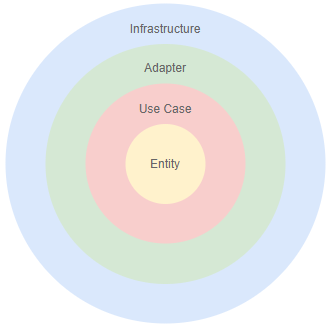
円の数
4つの円によってソフトウェアを分類するというのはあくまで基本的なパターンであり、独自にレイヤーを定義してもよい。最終的な目標は依存関係の管理と関心事の分離であり、開発者間で認識を共有しソースコードをレイヤーに分類できれば問題ない。
(認識共有という意味で汎用的なパターンに従うメリットは大きいので、github flowとgit flowみたいにプロジェクトの規模に合わせたパターンが整備されると嬉しいですが…)
例えば個人開発の場合ビジネスルールEntityとアプリケーションのルールUseCaseは区別されないことが多く、その場合3層でも十分だと思われる。
各層の詳細説明
Entity
Entityレイヤーはビジネスルールを取り扱う。ここで言うビジネスルールとはアプリケーションに依存しないルールだと思われる。
エンティティは、企業全体の最重要ビジネスルールをカプセル化したものだ。エンティティは、メソッドを持ったオブジェクトでも、データ構造と関数でも構わない。企業にあるさまざまなアプリケーションから使用できるなら、エンティティは何であっても問題はない。企業が存在せず、単一のアプリケーションを作成しているだけなら、エンティティはアプリケーションのビジネスオブジェクトになるだろう。
Robert.C.Martin; 角 征典; 高木 正弘. Clean Architecture 達人に学ぶソフトウェアの構造と設計 (アスキードワンゴ) (p.251). 株式会社ドワンゴ. Kindle版.
UseCase
UseCaseレイヤーはアプリケーション固有のルールを取り扱う。
ユースケースのレイヤーのソフトウェアには、アプリケーション固有のビジネスルールが含まれている。ここには、システムのすべてのユースケースがカプセル化・実装されている。ユースケースは、エンティティに入出力するデータの流れを調整し、ユースケースの目標を達成できるように、エンティティに最重要ビジネスルールを使用するように指示を出す。
Robert.C.Martin; 角 征典; 高木 正弘. Clean Architecture 達人に学ぶソフトウェアの構造と設計 (アスキードワンゴ) (pp.251-252). 株式会社ドワンゴ. Kindle 版.
Adapter
Adapterレイヤーは
境界をまたぐとき
クリーンアーキテクチャでレイヤーをまたぐときはHumble Object パターンを用いることが推奨される。
HumbleObjectパターンは実装をテストしづらいHumble(控え目)なものとそうでないものに分割するというデザインパターンで、テスト容易性を向上させる。「データベースに繋げてテストしたくないから、モックつくっとこ!」と言った素朴な気持ちを一般化したものだと思われる。
クリーンアーキテクチャの文脈でいうHumbleObjectは他のレイヤーのことであり、ステートレスなオブジェクト(構造体)を境界に定義して、そのオブジェクトを通してのみ境界をまたげるようにすることで実現される。
クリーンアーキテクチャで出てくる用語
プレゼンター
アダプター層で具体的に実装されるユースケース層のデータ形式からインフラストラクチャー層のデータ形式への変換機能のこと。PythonでUserというエンティティをユーザ用とデータベース用に変換するケースを例に挙げると以下のようになる。
# presenters/user_ui_presenter.py
from usecase.get_user import GetUserOutput
from datetime import datetime
class UserUIPresenter:
@staticmethod
def present(user: GetUserOutput) -> dict:
return {
"id": user.id,
"name": user.name.upper(), # 例: 大文字に変換
"email": user.email,
"created_at": datetime.fromisoformat(user.created_at[:-1]).strftime("%Y-%m-%d %H:%M:%S"),
}# presenters/user_db_presenter.py
from usecase.get_user import GetUserOutput
class UserDBPresenter:
@staticmethod
def present(user: GetUserOutput) -> dict:
return {
"user_id": user.id,
"full_name": user.name, # DBではフルネームのカラムがあるかもしれない
"email_address": user.email,
"created_at": user.created_at, # DBはISO8601のまま保存
}こんな回りくどいものをつくらず、ユースケース層やインフラストラクチャ層に変換ロジックを格納してはいけないのだろうか。
ユースケース層はあくまでユースケース層よりも内側で閉じた結果しか扱わないので、外側の層がどのように結果を扱うかを気にしたくはない。そのためロジックを寄せるのであればインフラストラクチャ層になる。
しかし、インフラストラクチャ層がユースケース層の結果を直接変換するとテストが難しくなる。これはインフラストラクチャ層が外部ライブラリの詳細を含むためである。
jinjaやmustacheなどのテンプレートを使ってWebをレンダリングするよくあるフレームワークを想像すると理解がしやすい。jinjaに変数を格納してユーザに表示する部分はインフラストラクチャ層になり、この部分のテストは難しい。外部ライブラリに依存するため、ともすればデータベースの設定など余計な詳細もすべて含まれてしまう(djangoを想像するとよいと思う)。もしこの表示レイヤに変換ロジックも格納されていると、表示結果のレグレッションテストなどは実装しづらくなる。
そこでアダプター層が登場する。この層が変換規則を担当することでテストを純粋な形で保ってくれる。


コメント